인트로
안녕하세요. 오늘은 Spring 환경에서 특정 사이트(네이버 날씨) 데이터를 크롤링으로 가져와보도록 하겠습니다.
Spring 환경에서 특정 사이트의 데이터를 크롤링해오려면 Jsoup 라이브러리가 필요합니다.
목차
1. Jsoup 구성 요소
2. Spring에 Jsoup 의존성 주입(DI)
3. 특정 사이트의 CSS 분석
4. 날씨 정보 크롤링
5. 코드 상세 설명
| Jsoup 개념 및 구성 요소 |
Jsoup이란? HTML을 파싱하는 Java 라이브러리 입니다. DOM, CSS 및 Jquery와 같은 방법을 사용하여 데이터를 추출하고 조작하는 API를 제공합니다.
- Document : jsoup으로 크롤링해온 결과 HTML 문서
- Element : Document 의 HTML 요소
- Elements : Element 들이 모인 자료형
| Spring에 Jsoup 의존성 주입 |
JAVA에서 데이터를 크롤링하기 위해서는 'Jsoup' 이라는 라이브러리가 필요합니다.
의존성 주입을 위해 jsoup 라이브러리를 프로젝트의 pom.xml에 추가해 줍니다.
<dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.11.2</version> </dependency>| 특정 사이트의 CSS 분석하기 |
네이버 날씨 사이트에 들어가 CSS를 분석해봅니다.
네이버 날씨 사이트 : weather.naver.com/today
오늘의 날씨 이미지는 다음과 같이 되어있었고, 코드는 다음 형식으로 되어있습니다.
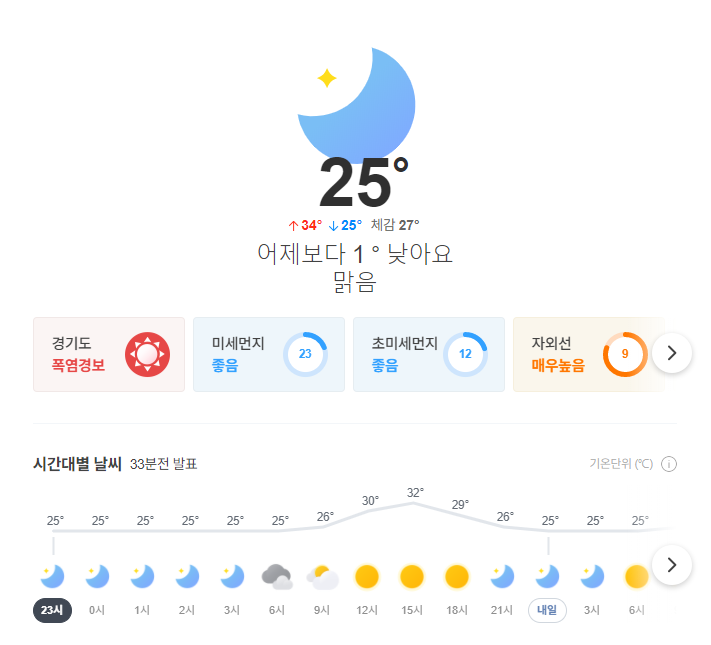
<p class="summary ">어제보다 <span class="summary_temperature">1</span> ° 낮아요<br> <span class="weather">맑음</span> <a href="#hourly" class="link_rainfall" role=“button”>시간당 강수량 <strong>0mm</strong></a> </p>
제가 얻고자 하는 '맑음' 정보가
<p>태그의 summary 클래스, <span>태그의 weather클래스에 감싸져 있는 것을 볼 수 있습니다.
| 네이버 날씨 정보 크롤링 |
아래와 같은 코드를 작성해 네이버 날씨 사이트의 날씨 정보를 크롤링해옵니다.
String WeatherURL = "https://weather.naver.com/today"; Document doc = Jsoup.connect(WeatherURL).get(); //HTML로 부터 데이터 가져오기 Elements elem = doc.select(".weather_area .summary .weather");//원하는 태그 선택 String[] str = elem.text().split(" ");//정보 파싱 model.addAttribute("weather", elem); System.out.println(elem);
| 코드 상세 설명 |
1) 사이트 연결 및 데이터 저장 : WeatherURL로부터 HTML 문서 가져오기
Document doc = Jsoup.connect(WeatherURL).get();
2) 원하는 태그 선택 : 본문 HTML 요소 가져오기
Elements elem = doc.select(".weather_area .summary .weather");
3) 데이터 파싱: 공백을 기준으로 데이터 나누기
String[] str = elem.text().split(" ");
특정 사이트의 데이터를 크롤링을 통해 가져오는 방법을 소개해드렸습니다.
크롤링의 개념이 어려운 줄 알았지만, 해내고 나니 생각보다 쉽고 간단한 것을 알 수 있었습니다.
감사합니다 :)
'BE > Spring' 카테고리의 다른 글
| [Spring] @Autowired 와 DI 개념 정리 (0) | 2021.02.08 |
|---|---|
| [Spring][JAVA] Spring 개념 정리 (AOP,POJO,JDBC 등) (0) | 2020.11.04 |
| [Spring] 네이버 API 데이터 연동 방법 (1) | 2020.11.01 |
| [Spring] 스프링 한글 깨짐 문제 인코딩 해결 (0) | 2020.08.13 |
| [Spring] 메이븐(Maven)과 pom.xml (0) | 2020.07.13 |



